Run AI agents at
80% lower cost
The optimized infrastructure layer for autonomous systems. Host agent logic on affordable CPU Virtual Servers and route inference to high-performance GPUs. All with zero egress fees.


nodes.garden


nodes.garden
Why Fluence for AI agents
Fluence provides the infrastructure primitives needed to run agents reliably without stitching together multiple compute products.

Agent logic (CPU)
Host long-running orchestration, tool routing, memory, and APIs on standard Linux Virtual Servers. Low cost, always on.
Host long-running orchestration, tool routing, memory, and APIs on standard Linux Virtual Servers. Low cost, always on.
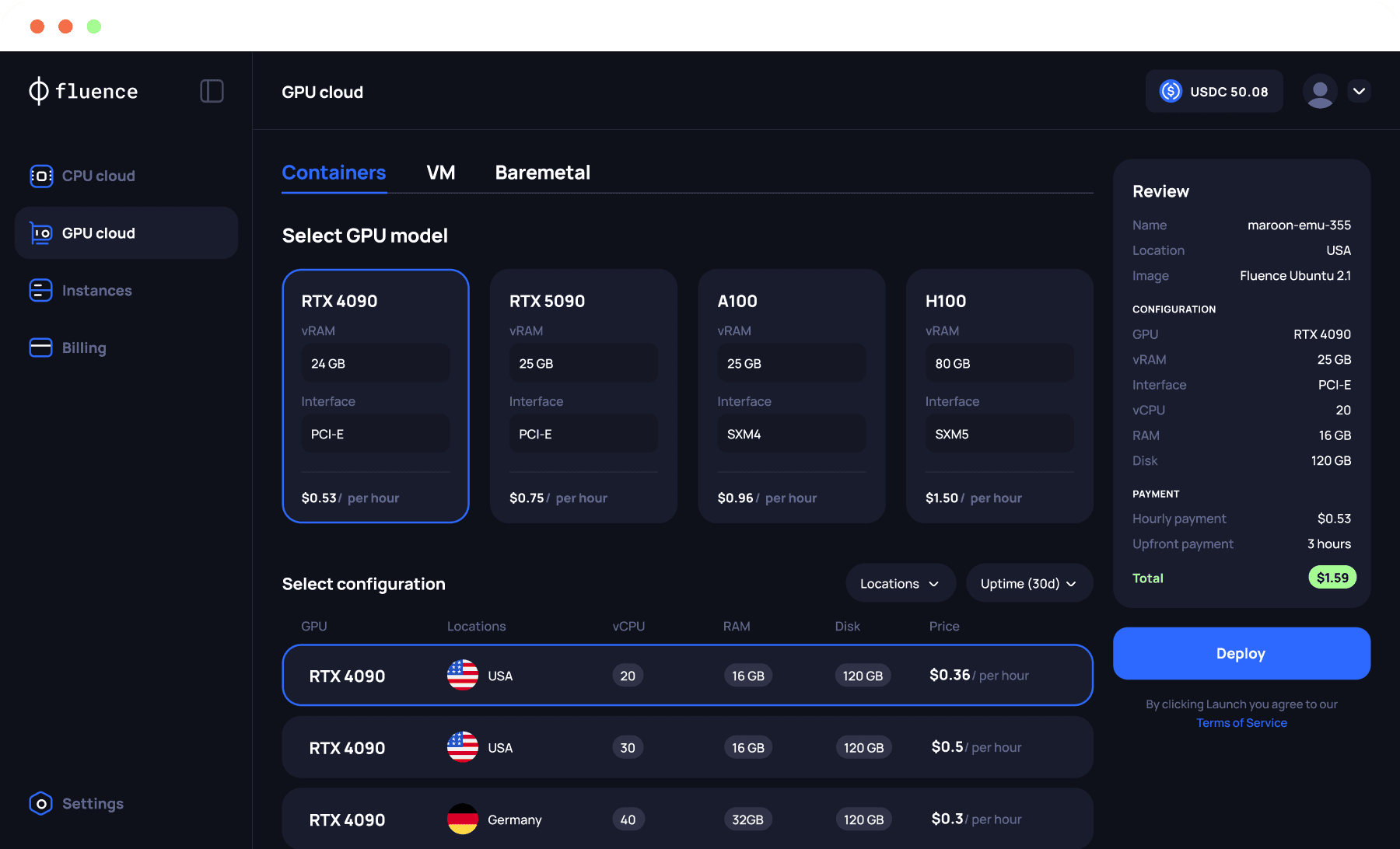
On-demand inference (GPU)
Connect your agents to GPU containers only when needed. Serve models yourself to reduce API costs and latency.

No vendor lock-In
Deploy across Tier-3/4 datacenters globally. Mix and match providers, regions, and hardware to ensure redundancy.
Deploy across Tier-3/4 datacenters globally. Mix and match providers, regions, and hardware to ensure redundancy.


Zero egress fees
Agents move a lot of data. We don't tax it. Enjoy unlimited bandwidth and simple flat-rate pricing (Daily for CPUs, hourly for GPUs).
Running AI agents on Fluence vs Centralized cloud
Running AI agents on Fluence vs Centralized cloud
Feature
Big cloud
Fluence
Pricing
Complex plans
and add ons
Simple daily and hourly rates
Bandwidth
Metered with egress fees
Unlimited with zero egress fees
Control
Tied to one provider stack
Multiple providers and locations
Deployment
Fragmented services
Fluence API for provisioning and management
Pricing
Complex plans
and add ons
Simple daily and hourly rates
Bandwidth
Metered with egress fees
Unlimited with zero egress fees
Control
Tied to one provider stack
Multiple providers and locations
Deployment
Fragmented services
Fluence API for provisioning and management

How it works
Connect your hardware and start earning in three steps
Connect your hardware and start
earning in three steps

1
1
Run agent services
on CPU virtual servers
Run agent services on
CPU virtual servers.
Run agent services on CPU
virtual servers
Run agent services on CPU virtual servers.
Deploy your orchestration logic, vector DBs, and tool interfaces on cost-effective CPU Virtual Servers.
Deploy your orchestration logic, vector DBs, and tool interfaces on cost-effective CPU Virtual Servers.
2
2
Connect to your
model source
Connect to your model source
Connect to your model source
Route inference tasks to Fluence GPU containers for open-source models, or connect to external APIs for proprietary models.
Earn stable USDC, FLT availability rewards,
and FLOPS incentives.
Route inference tasks to Fluence GPU containers for open-source models, or connect to external APIs for proprietary models.
3
3
Console for launch,
API for scale
Console for launch, API for scale
Console for launch, API for scale
Launch quickly in the console. Use the API to automate deployment, rotation, and cost controls.
No net-30/60 terms. Get paid immediately
upon job completion.
Launch quickly in the console. Use the
API to automate deployment, rotation,
and cost controls.
Use cases
Use cases
Use cases
Agent platforms
Run agent logic, tools, memory, and model endpoints on one platform with transparent pricing.
Agent platforms
Run agent logic, tools, memory, and model endpoints on one platform with transparent pricing.
Agent platforms
Run agent logic, tools, memory, and model endpoints on one platform with transparent pricing.
Enterprise Operations
Deploy support and ops agents close to your internal systems. Choose specific regions to keep latency low and security high.
Enterprise Operations
Deploy support and ops agents close to your internal systems. Choose specific regions to keep latency low and security high.
Enterprise Operations
Deploy support and ops agents close to your internal systems. Choose specific regions to keep latency low and security high.
DePIN & blockchain automation
DePIN & blockchain automation
Run 24/7 listeners that monitor blockchains, index data, and trigger events. Proven stability for gateway and node workloads.
Run 24/7 listeners that monitor blockchains, index data, and trigger events. Proven stability for gateway and node workloads.
Run 24/7 listeners that monitor blockchains, index data, and trigger events. Proven stability for gateway and node workloads.
DePIN & blockchain automation
Run 24/7 listeners that monitor blockchains, index data, and trigger events. Proven stability for gateway and node workloads.
Research & experimentation
Research & experimentation
Spin up CPU and GPU environments for testing new models. Tear them down instantly via API when the experiment ends.
Spin up CPU and GPU environments for testing new models. Tear them down instantly via API when the experiment ends.
Spin up CPU and GPU environments for testing new models. Tear them down instantly via API when the experiment ends.



A global marketplace
of compute
Source the exact CPU and GPU resources your agents need from top-tier providers like Sestre, Akash, and TensorDock—unified in one console.

A global marketplace
of compute
Source the exact CPU and GPU resources your agents need from top-tier providers like Sestre, Akash, and TensorDock—unified in one console.
A global marketplace
of compute
Source the exact CPU and GPU resources your agents need from top-tier providers like Sestre, Akash, and TensorDock—unified in one console.

On-demand or spot instances
On-demand or spot instances
Choose high-availability instances for
maximum stability and reliability, or leverage
spot instance pricing for cost savings.
Choose high-availability instances for maximum stability and reliability, or leverage spot instance pricing for cost savings.
Choose high-availability instances for
maximum stability and reliability, or leverage
spot instance pricing for cost savings.
Automate with Fluence API
Automate with Fluence API
Automate with
Fluence API
Find providers, launch custom OS images
in seconds, and manage large multi-agent
systems programmatically.
Find providers, launch custom OS images in seconds, and manage large multi-agent systems programmatically.
Find providers, launch custom OS images
in seconds, and manage thousands of GPU servers programmatically.

Coming soon
FAQ
How do I connect my logic to my models?
Can I use custom OS images
Do I need both virtual servers and GPU containers
Can I separate agent logic from inference
Show more
Can I separate agent logic from inference
How do I connect my logic to my models?
Can I use custom OS images
Do I need both virtual servers and GPU containers
Show more

Run AI agents at
80% lower cost
The optimized infrastructure layer for autonomous systems. Host agent logic on affordable CPU Virtual Servers and route inference to high-performance GPUs. All with zero egress fees.
nodes.garden
Why Fluence for AI agents
Fluence provides the infrastructure primitives needed to run agents reliably without stitching together multiple compute products.
Agent logic (CPU)
Host long-running orchestration, tool routing, memory, and APIs on standard Linux Virtual Servers. Low cost, always on.
On-demand inference (GPU)
Connect your agents to GPU containers only when needed. Serve models yourself to reduce API costs and latency.
No vendor lock-In
Deploy across Tier-3/4 datacenters globally. Mix and match providers, regions, and hardware to ensure redundancy.
Zero egress fees
Agents move a lot of data. We don't tax it. Enjoy unlimited bandwidth and simple flat-rate pricing (Daily for CPUs, hourly for GPUs).
Running AI agents on Fluence vs Centralized cloud
Feature
Big cloud
Fluence
Pricing
Complex plans
and add ons
Simple daily and hourly rates
Bandwidth
Metered with egress fees
Unlimited with zero egress fees
Control
Tied to one provider stack
Multiple providers and locations
Deployment
Fragmented services
Fluence API for provisioning and management
How it works
Connect your hardware and start earning in three steps
1
Run agent services
on CPU virtual servers
Deploy your orchestration logic, vector DBs, and tool interfaces on cost-effective CPU Virtual Servers.
2
Connect to your
model source
Route inference tasks to Fluence GPU containers for open-source models, or connect to external APIs for proprietary models.
3
Console for launch,
API for scale
Launch quickly in the console. Use the API to automate deployment, rotation, and cost controls.
Use cases
Agent platforms
Run agent logic, tools, memory, and model endpoints on one platform with transparent pricing.
Enterprise Operations
Deploy support and ops agents close to your internal systems. Choose specific regions to keep latency low and security high.
DePIN & blockchain automation
Run 24/7 listeners that monitor blockchains, index data, and trigger events. Proven stability for gateway and node workloads.
Research & experimentation
Spin up CPU and GPU environments for testing new models. Tear them down instantly via API when the experiment ends.
A global marketplace
of compute
Source the exact CPU and GPU resources your agents need from top-tier providers like Sestre, Akash, and TensorDock—unified in one console.
On-demand or spot instances
Choose high-availability instances for
maximum stability and reliability, or leverage
spot instance pricing for cost savings.
Automate with Fluence API
Find providers, launch custom OS images
in seconds, and manage large multi-agent
systems programmatically.
Coming soon
FAQ
How do I connect my logic to my models?
Can I use custom OS images
Do I need both virtual servers and GPU containers
Can I separate agent logic from inference
Show more